How does artificial intelligence process data? There are probably two ways of long-term coexistence
How does artificial intelligence process data? If the focus is on the way data is processed, there are probably two ways to coexist for a long time:
Feature learning is also called representation learning or representation learning.
Feature engineering mainly refers to the artificial processing and extraction of data, and sometimes also refers to "washing data".
It is not difficult to see that the main difference between the two is that the former is a "learning process" while the latter is considered a "man-made project". In a more vernacular way, feature learning is a method of automatically extracting features or representations from data. This learning process is model-autonomous. The process of feature engineering is to artificially process the data to get the style we think is suitable for subsequent models.
To give a simple example, deep learning is a kind of representation learning, and its learning process is a process of extracting effective features. The useful features are extracted after layer-by-layer learning, and finally handed over to the subsequent classification layer for prediction.
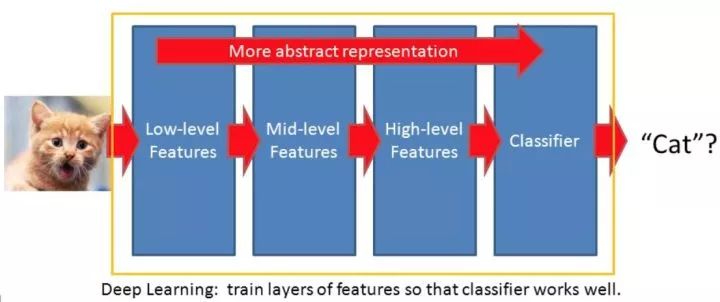
A less rigorous but intuitive understanding can be, assuming an n-layer deep learning network, then the input data is abstracted layer by layer by the network, and the upper layers (1~k) have learned low level features. ), the middle layer (k+1~m) learned the middle level features, and the later layer (m+1~n-1) features reached a high level of abstraction and obtained high-level features ( high level features), the final highly abstract features are applied to the classification layer (n), thus obtaining a good classification result.
A common example is that the first few layers of a convolutional network can learn the "concept of edges", and then the "concept of angles", and gradually learn more abstract and complex such as "concepts of graphics".
The following figure gives an intuitive example, that is, the image gets highly abstract and effective features after deep network learning, which is used as the input data of the prediction layer, and the final prediction target is a cat.
Another common example is the following figure. The deep belief network uses stacked restricted Boltzmann machines (Stacked RBM) to learn features. Unlike cnn, this process is unsupervised. The reason for stacking RBF is to gradually transfer the features learned by the bottom RBF to the upper RBF, and gradually extract complex features. For example, from left to right in the figure below, it can be the features learned by the low-level RBF to the complex features learned by the high-level RBF. After these good features are obtained, they can be transferred to the traditional neural network at the back end for learning.

To put it another way, the layer-by-layer network of deep learning can automatically learn useful and highly abstract features from the data, and the ultimate goal is to help the classification layer make good predictions. And why does deep learning work well? Probably it has nothing to do with its ability to effectively extract features.
Of course, a major feature of deep learning is its distributed representation of data (*also related to other characteristics such as sparse representation). The most intuitive example can be word2vec in nlp, where each word is no longer Separate and related to each other. Similarly, parameter sharing in many networks is a distributed representation, which not only reduces the amount of parameters required but also improves the ability to describe data. Looking only at the classification layer, deep learning and other machine learning seem to be no different, but it is precisely because of all kinds of good representation learning capabilities that make it stand out.
The following figure intuitively compares the two feature learning methods we mentioned above. Traditional machine learning methods mainly rely on manual feature processing and extraction, while deep learning relies on the model itself to learn the representation of data.
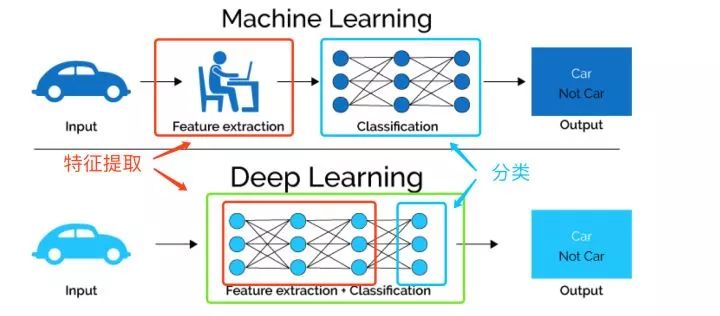
In summary, the processing of data by machine learning models can be roughly classified into two directions: Representation learning: The model automatically learns the input data to obtain features that are more conducive to use (*may also make predictions).
Representative algorithms generally include: Deep learning, including most common models such as cnn/rnn/dbn, and some unsupervised learning algorithms such as transfer learning, such as principal component analysis (PCA), which transforms the input data to make the input data more Meaningful Some tree models can automatically learn the features in the data and make prediction feature engineering at the same time: the model relies on the data features that are processed by humans, and the main task of the model is prediction, such as simple linear regression expecting good input data (such as Discretized data) It should be noted that this classification method is not rigorous and is only for intuitive purposes. There is no division to say that algorithm a is learning, and algorithm b is not. It is just a division that is easy to understand.
Therefore, most of the models are between pure representation learning and purely relying on artificial features, with different degrees, and there are few absolute automatic learning models.
So curious readers will ask:
1. Is automatic feature extraction (representation learning) always better?
The answer is not necessarily:
When the amount of data is not enough, automatic feature extraction methods are often inferior to artificial feature engineering.
When users have a deep understanding of data and problems, manual feature engineering often works better.
An extreme example is that feature engineering in kaggle competitions can always bring some improvement, so manual feature extraction and processing are still useful.
At the same time, it is also worth noting that another benefit of representation learning is that highly abstract features can often be applied to related fields. This is also the idea of ​​transfer learning that we often call. For example, after there are a large number of cat pictures, it can not only be used to predict whether an object is a cat, but also can be used to apply the extracted features to other similar fields to save data overhead.
2. What is the relationship between feature learning (representation learning), feature engineering, feature selection, and dimension compression?
From a certain perspective, it means that learning has the characteristic of "embedded feature selection", which means that learning is embedded in the model.
For a simple example, the decision tree model can learn the importance of different features at the same time during the training process, and this process is part of the modeling, which is an embedded feature selection.
Coincidentally, representation learning is also an embedded representation. For example, the dimensional compression method PCA is also a process of finding suitable low-dimensional embedding for high-dimensional data. The word2vec mentioned above is also another kind of "embedding". As for whether this "embedding" must be high-dimensional to low-dimensional, it is not necessarily but often because the features are abstracted. One of the two types of embedding mentioned above is the embedding of the model, and the other is the embedding in the dimension, which is mainly a coincidence in the name.
3. How can understanding different data processing methods help us?
First of all, it is helpful for model selection: When we have a small amount of data and have a good understanding of the data, artificial feature processing, which is feature engineering, is appropriate. Such as removing irrelevant data, selecting suitable data, merging data, discretizing data, etc. When the amount of data is large or our human prior understanding is very limited, we can try to express learning, such as relying on deep learning in one go, the effect is often good.
4. Why do some models have the ability to express learning, but some do not?
This issue needs to be discussed in different models. Taking deep learning as an example, feature learning is an understanding of the model, not the only understanding, and why the generalization effect is good, there is still a lack of systematic theoretical research.
5. Feature engineering refers to the cleaning of data. What does it have to do with learning?
What we want to emphasize here is that this is not a rigorous scientific division, but an intuitive understanding. If the model used has data simplification, feature representation and extraction capabilities, we can all consider it to have the characteristics of representation learning.
As for which model counts and which model does not count, there is no need to entangle this point. Feature engineering in a narrow sense refers to various preprocessing methods such as processing missing values, feature selection, and dimensional compression. From a larger perspective, the main purpose is to improve the ability of data representation. The artificial refinement of data to make it better expressed, this is actually artificial representation learning.
Written at the end, this answer is only an understanding of data processing methods in machine learning, not the only correct view. In view of the rapid change of knowledge in the field of machine learning, personal knowledge reserves are also limited, which is for reference only.
The advantage of entertainment tablet lies in having a powerful chip and excellent hardware. If you want to play various online videos on the tablet and run various software smoothly, the performance of the hardware is an absolute prerequisite. In addition, a high-speed and stable WIFI module is also required, which must be compatible with multiple 802.11 B/G/N protocols at the same time, so that the webpage can be loaded instantly when the webpage is opened, and the online video can be played smoothly. So hardware is the premise and foundation, without good performance everything else is empty talk.
In addition to having a good CPU as a prerequisite, it is equally important to carry a professional video player. A professional video player must perform equally well both online and offline.
Entertainment Tablet,High capacity battery Tablet,WIFI Tablet
Jingjiang Gisen Technology Co.,Ltd , https://www.gisengroup.com