Introduced the relationship between C language and machine language and the implementation mechanism of other types of language
We know that programs written in any programming language are ultimately executed by the underlying machine's machine code (01 sequence), whether it is a compiled or interpreted language. The source code of any high-level programming language program is a sequence of characters. The sequence of characters to the underlying 01 sequence is completed by multiple conversions by the compiler or parser.

Figure 1 Hierarchy of programming languages
In this hierarchy, from high to low is getting closer to machine hardware. The machine code is the 01 sequence. The assembly language is the instruction set architecture that describes the local machine. The high-level language contains the corresponding data structure and grammatical structure, which is closer to human language habits. Therefore, the higher the level, the more oriented it is to humans. In computer science, the CPU is abstracted into an instruction set architecture that describes all the functions that the CPU does. All programs are compiled or interpreted into machine programs represented by this instruction set. Instructions in the instruction set can be divided into functions by function:
1. Data transfer instruction for reading and writing memory and registers.
2. Arithmetic and logical operation instructions, such as: addl performs double word (32bit) addition, andl double word bitwise AND.
3. Control flow instructions for implementing control structures such as branches and loops in high-level programming languages.
4. Procedure call instructions are used to implement function calls, allocate and restore stack frames, and so on.
Any program needs to be converted into a sequence of instructions for an instruction set, such as the following simple C program for factorial:
[cpp] view plaincopyprint?int fact_while(int n)
{
Int result = 1;
While (n > 1) {
Result *= n;
n = n-1;
}
Return result;
}
On a 32-bit machine, the x86 instruction sequence after gcc compilation is:
[plain] view plaincopyprint? movl 8(%ebp), %edx
Movl $1, %eax
Cmpl $1, %edx
Jle .L7
.L10:
Imull %edx, %eax
Subl $1, %edx
Cmpl $1, %edx
Jg .L10
.L7:
By observing the machine code of the C program, it can be found that the C program is converted into machine code, mainly with the conversion of the data type and the control structure. The following is explained in the x86 instruction set:
1. Data type conversion: At the bottom level, x86 instructions are not logically typed for data, that is, no int, float, double. All data is classified into words (16 bytes, Word), double words (32 bytes, Double Words), and four words (64 bytes, Quad Words) according to the number of bytes it occupies. The data type of an instruction operation is represented by the suffix of this instruction, such as the mov instruction, the movw operation word, and the movl operation double word. That is to say, the different data types in the high-level language program reflected on the underlying instruction set mainly reflect the difference of the instructions. For example, if the result type in the above C program is changed to short, the mov instruction in the corresponding assembly code will be converted from movl to movw. Of course, there is another problem is how the specific data types in the C language are stored in the machine code. This should be the responsibility of the gcc compiler. For example, for int, gcc needs to know how the underlying instruction set encodes int, what encoding is used, whether the byte order is Big-endian or Little-endian. After knowing the underlying implementation, gcc can encode a string representing an integer number into the corresponding binary form. For data structures such as arrays, structs, and unions, they are converted to the corresponding memory address plus offset.
2. Control structure conversion: The control structure is the flow of executing instructions. In x86, all instruction sets are executed sequentially. To implement branches, loops, etc., you must have a jump instruction in the form of go, and a corresponding conditional judgment instruction. The CPU has a set of condition code registers that indicate the state of the arithmetic or logic operation (whether the result of the calculation overflows, is 0 or a negative number, etc.). The conditional operation instruction can test a condition, such as "cmpl $1, %edx" compares the size of the number stored in direct number 1 and register %edx, and stores the result in the condition code register. Next, a conditional jump instruction is executed, and it is judged based on the state in the condition code register whether or not to jump. For example, "jg .L10" jumps to L10 if the result of the previous cmpl instruction returns greater than, otherwise the next instruction is executed.
Of course, when making a function call, it is also described in the underlying machine code. We know that in computer science, a stack is used to implement a function call (called a call stack), and a stack frame is stored in the stack. Each function call corresponds to a stack frame, and the stack frame contains data such as local variables of the method, saved register values, and the like. The calling and returning of such a function corresponds to the stacking and popping of the stack frame. Two of the CPU's register banks are dedicated to implementing method calls, %esp and %ebp. %esp is the stack pointer register that holds the memory address at the top of the current function stack. %ebp is the frame pointer register, and the sequence of memory addresses between %esp and %ebp corresponds to the stack frame of the current function. Since the function call and return are closely related to the stack frame, the function call procedure can be described as:
1. Initialize the stack frame of the called function and push it onto the stack. That is, the function procedure is called, which is implemented by a call instruction.
2. Execute the called function.
3. Resume the stack frame of the calling function and pop the stack frame of the called function. That is, the process of returning the function is implemented by the ret instruction.
For the initialization, recovery stack frame is actually the adjustment of %esp and %ebp, but also the problem of passing parameters and return values, which are all implemented by the compiler.
The relationship between C language and machine language is introduced above. Let's look at the implementation mechanism of other types of languages. First, we can divide programming languages ​​into compiled languages, interpreted languages, and virtual machine languages. Compiled languages ​​are compiled directly into native machine code, such as C and C++. Explanatory languages ​​are executed by an interpreter such as javascript, shell, python, etc. The virtual machine language runs on the virtual machine and needs to be compiled into virtual machine code, which is executed by the virtual machine, such as java. Although Python also has its own virtual machine, it does not need to be compiled, so it is classified as an interpreted language.
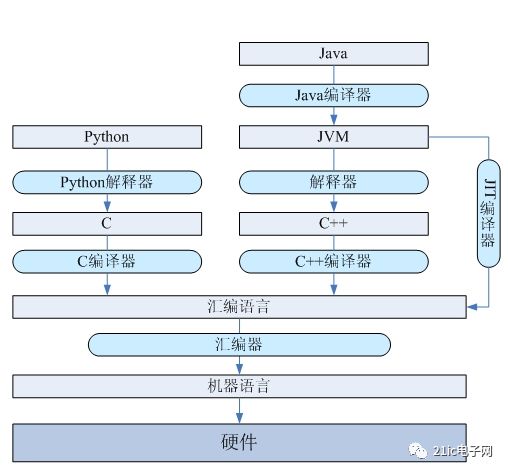
Figure 2 programming language implementation structure
Through the above analysis, we know that the most important for a language is the data type, control structure and syntax structure, and system calls. As you can see from the above figure, C and C++ are closer to the underlying hardware, but you can't directly access hardware such as registers like assembly language. Python and Java have a higher level of abstraction than C and C++, and they cannot access memory directly through pointers. From machine language -> assembly language -> system language (C and C + +) -> interpreted language (python) and virtual machine language (java), the level of abstraction is getting higher and higher, the closer to human thinking, do not need to consider More detail; at the same time, programmers' freedom and programs are running at a lower and lower speed. Let's discuss it from low to high.
At the bottom level, assembly language is converted to machine code by the assembler. For example, when compiling a C program with gcc, the assembler is called for assembly. Through the level of assembler and assembly language, the implementation details of the underlying machine hardware can be well isolated. Different processors have corresponding assemblers that assemble assembly language into a set of instructions supported by the processor. This is to achieve the portability of the assembly language layer.
In the C and C++ system programming languages, the mapping of language elements to assembly language is done through the compiler. For example, the conversion of data types, control structures, function calls, etc., as described above.
Python is an interpreted language that implements mapping to the underlying language through a Python interpreter. We know that the python virtual machine is written in C, so the python program will be converted to a C program and executed. For example, all objects in Python will have a corresponding PyObject structure in C. Python's list, dict and other data types should also have a corresponding representation in C. Grammatical structures such as generators and iterators require corresponding support.
A virtual machine is a program that emulates an instruction set, so it has its own set of instructions that are independent of the specific hardware and operating system. This set of instructions needs to be implemented in the underlying language. The virtual machine itself also has its own data type system, language structure and so on. For example, the data types supported by the java virtual machine have basic data types and reference types, and also support bytecode instructions such as tableswitch and lookupswitch that implement the switch syntax structure. The way these language elements are mapped to the underlying language can be implemented differently. The first is that the interpreter mode is converted to C++, and the JIT directly compiles the native machine code.
A virtual machine language such as java will be compiled into the virtual machine's local machine code by the compiler, and then executed on the virtual machine. Here, you need to implement the java language data type, language structure and data on the java virtual machine to the javac compiler. A mapping of types and grammatical structures.
By talking, you can see the importance of compilers and interpreters and virtual machines in programming languages, which are the cornerstones of programming languages ​​that can run on computers. A programming language compiler, interpreter, or virtual machine can greatly affect the execution efficiency of the language. Because they do a lot of optimization when doing language conversion to improve execution efficiency. That's why there are so many good languages ​​on the JVM, because the JVM is very powerful. Therefore, to penetrate the bottom of the language, you must learn the compiler, interpreter and virtual machine implementation, this aspect still needs to work hard.
Waterproof D-Sub Connector & D-SUB Adapter
IP66 / IP67 waterproof d-sub connectors-Designed for IP Performance
ANTENK has developed IP66 / IP67 waterproof d-sub connectors that utilize a proprietary sealing technology, which maintains the same physical size and footprint as standard d-sub products.
Antenk's line of Waterproof d-sub connectors utilize an innovative sealing technology eliminating the need to redesign enclosures and PC boards when implementing IP67 design upgrades.These connectors are designed for applications that require protection from heavy spray or are exposed to short-term submersion. Connectors are available in vertical and right angle board mount types as well as solder cup for panel mount cable applications. Standard D-Subs are available in 9 pin, 15 pin, and 25 pin positions, and high density D-Subs are available in 15 pin, 26 pin, and 44 pin positions
Applications of Antenk waterproof d-sub connectors:
Hand held computers, scanners, and printers that are used outdoors
Remote sensors, gauges, and data loggers that are used outdoors
Industrial and Medical equipment that is routinely subject to wash down
Transmitters and emergency beacons that are subject to temporary submersion
Gas, Electric, and Water metering systems that have embedded Smart Grid electronics
Portable electric generation equipment (Gen Sets)
Consumer and Commercial boating electronics (Radios, Scanners, Radar, DC Power Ports)
IP67 D-SUB | WATERPROOF CONNECTORS FEATURES & BENEFITS
Signal / Low Power in 6 standard size
(Standard: 9 pin, 15 pin, 25 pin | High Density: 15 pin, 26 pin,44 pin)
Combo-D / High Power in a variety of configurations:
(3W3, 5W5, 7W2, 9W4, 11W1, 13W3, 13W6, 17W2, 21W1, 21WA4)
Solder Cup, Vertical Mount & Right Angle Board Mount Options
High Reliability Screw Machined Contacts
3 amp / 5 amp / 20 amp / 40 amp Power Options
-65°C to +105°C Operating Temperature Range
Range of Antenk waterproof d-sub connectors
solder cup, stamped & formed contact D-sub waterproof
solder cup,machined contacts D-sub waterproof
vertical mount D-sub waterproof
right angle D-sub waterproof
IP67 rated Combo power D-sub waterproof
D-Sub adapters, couplers, and splitters
Solder Cup Waterproof D-Sub Connector,Vertical Mount Waterproof D-Sub Connector, Right Angle Waterproof D-Sub Connector,Combo Power D-Sub Waterproof D-Sub Connector,Waterproof D-Sub Connector,D-SUB Adapter,IP66/ IP67/IP68 Rated D-Sub Connectors
ShenZhen Antenk Electronics Co,Ltd , https://www.antenkcon.com