Named Entity Recognition (NER) is one of the basic tasks in Natural Language Processing (NLP)
What is Named Entity Recognition (NER)?
Named Entity Recognition (NER) is one of the basic tasks in natural language processing (NLP). The general process of NLP is as follows:

Syntactic analysis is the core of NLP tasks, and NER is the basis of syntactic analysis. The NER task is used to identify entities in the text such as person names (PER), place names (LOC), and so on. Non-entity is represented by O. We give examples by name:
King B-PER
I-PER
And O
Small B-PER
Li I-PER
Knot O
Marriage O
Now. O
(IOB is a representation of a block tag. B- denotes the beginning, I- denotes internal, O- denotes external)
First of all, it is clear that NER is a classification task, which is specifically called sequence labeling task, that is, different entities in the text correspond to different labels, name-PER, place-LOC, and so on. Similar sequence labeling tasks also have part-of-speech tagging and semantic roles. Callouts. Traditional methods for solving such problems include: (1) Rule-based methods. According to linguistically predefined rules. However, due to the uncertainty of the language structure itself, it is more difficult to formulate rules. (2) Statistically based method. Use statistics to find out the laws that exist in the text. There are mainly Hidden Markov (HMM), Conditional Random Field (CRF) models and Viterbi algorithm. The end of the article will briefly introduce the more popular CRF model. (3) Neural network. Deep learning (multi-layer neural network) is so popular, of course, will not miss nlp. In my previous post (“Deep learning in machine translation applicationâ€), we mentioned the recurrent neural network (RNN) and its variant LSTM. . Because of the contextual dependence of the text, LSTM, a sequence model capable of storing contextual information, is a better choice (this article focuses on CRF. The basic knowledge of LSTM can be found in "Application of Deep Learning in Machine Translation").
LSTM+CRF model
The special features of language texts are that they have a certain structure, subject and predicate complement, adverbial postposition, non-restrictive attributive clause, and so on. The existence of these structures means that there is a certain part-of-speech limitation before and after each word. such as:
I'm going home now //this is a common (primary + status + predicate + guest) structure sentence
The text of my family today // can't be called a sentence, and it lacks the necessary grammatical structure.
The LSTM network is the overall idea. It also learns the given training samples first, determines the parameters in the model, and then uses the model to predict the test samples to obtain the final output. Since the accuracy of the test output does not reach 100% at this stage, this means that there must be a part of the wrong output, which probably contains a non-grammatical text similar to the second sentence above. Therefore, this is the reason why the CRF model was introduced. Conditional Random Field (CRF) is a statistical method. Its advantage for labeling text sequences is that the output variables mentioned above can be constrained to conform to certain grammar rules. The common neural network learns training samples by considering only the input of training samples and does not consider the relationship between the outputs of training samples.
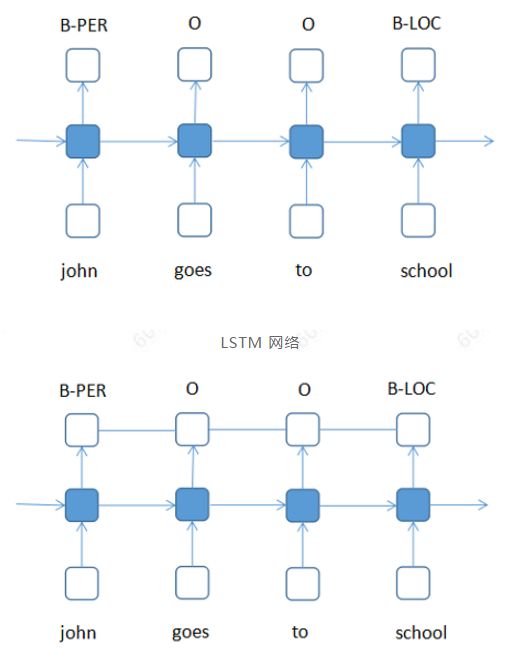
LSTM+CRF network
The LSTM network can be regarded as a multi-classification problem. Given labels such as B, I, and O as training output, and phrases like “john goes to school†as input, each word in a sentence is determined according to the probability of the network model. Which tag (category) has the highest probability is the last tag (category) to which the word belongs, and the tag and the tag are independent. LSTM+CRF is based on the classification problem, plus the constraint between the outputs. For example, after the "B" tag is still "B", this situation that does not meet grammar rules can be eliminated through the CRF mechanism. At present, tensorflow already supports the configuration of LSTM+CRF. (LSTM+CRF is a more classic model for deep learning, and there are currently other optimized models such as LSTM+cnn+CRF).
Attachment: Principle of Conditional Random Field (CRF)
To fully understand the principle of CRF, you can refer to Chapter 11 of Li Hang's Statistical Learning Method. Here is a brief explanation. The basis of CRF is Markov random field, or probability undirected graph.
extend
Probabilistic undirected graph: The undisturbed graph represents the probability distribution of random variables.
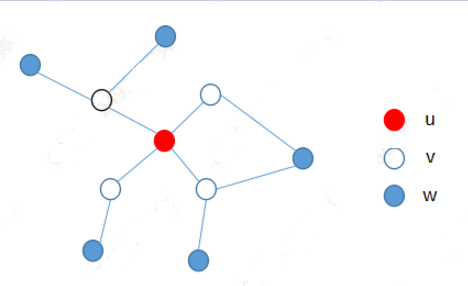
The figure above is a probability undirected graph that satisfies the local Markov property. Each node represents a random variable, and the edges represent the relationship between random variables.
Local Markov sex: P(Yu|Yv)=P(Yu|Yv,Yw) simply understands, because there is no edge connection between Yu and Yw, the probability of Yu under the condition of a given random variable Yv, followed by more A Yw has nothing to do.
CRF understanding
CRF can be understood as the Markov random field of random variable Y given the random variable X. Among them, the linear chain CRF (a special CRF) can be used for the sequence labeling problem. When CRF model is trained, given the training sequence sample set (X, Y), the parameters of the CRF model are determined by methods such as maximum likelihood estimation and gradient descent; in the prediction, the input sequence X is given, and the P is obtained according to the model. (Y|X) The largest sequence y (note here that the LSTM output is a separate category, the CRF output is the optimal class sequence, that is, the CRF global optimization is better).
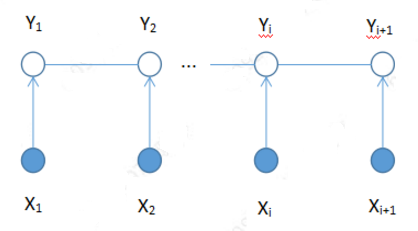
Linear chain conditional random field (can be compared with the above LSTM + CRF network diagram of the difference and contact)
Why does CRF represent the link between elements (Y1,Y2,...,Yi,Yi+1) in the output sequence? Here is to contact Markov sex. This is why the basis of CRF is Markov random field. CRF how to solve P (Y | X), there are specific mathematical formulas, not listed in detail here.
AURORA SERIES DISPOSABLE VAPE PEN
Zgar 2021's latest electronic cigarette Aurora series uses high-tech temperature control, food grade disposable pod device and high-quality material.Compared with the old model, The smoke of the Aurora series is more delicate and the taste is more realistic ,bigger battery capacity and longer battery life. And it's smaller and more exquisite. A new design of gradient our disposable vape is impressive. We equipped with breathing lights in the vape pen and pod, you will become the most eye-catching person in the party with our atomizer device vape.The 2021 Aurora series has upgraded the magnetic suction connection, plug and use. We also upgrade to type-C interface for charging faster. We have developed various flavors for Aurora series, Aurora E-cigarette Cartridge is loved by the majority of consumers for its gorgeous and changeable color changes, especially at night or in the dark. Up to 10 flavors provide consumers with more choices. What's more, a set of talking packaging is specially designed for it, which makes it more interesting in all kinds of scenes. Our vape pen and pod are matched with all the brands on the market. You can use other brand's vape pen with our vape pod. Aurora series, the first choice for professional users!
We offer low price, high quality Disposable E-Cigarette Vape Pen,Electronic Cigarettes Empty Vape Pen, E-cigarette Cartridge,Disposable Vape,E-cigarette Accessories,Disposable Vape Pen,Disposable Pod device,Vape Pods,OEM vape pen,OEM electronic cigarette to all over the world.






ZGAR Classic 1.0 Disposable Pod Vape,ZGAR Classic 1.0 Disposable Vape Pen,ZGAR Classic 1.0,ZGAR Classic 1.0 Electronic Cigarette,ZGAR Classic 1.0 OEM vape pen,ZGAR Classic 1.0 OEM electronic cigarette.
ZGAR INTERNATIONAL(HK)CO., LIMITED , https://www.zgarpods.com