Super-resolution neural network principle
After AlphaGo played against Li Shishi and Ke Jie, more industries began to try to optimize existing technical solutions through machine learning. In fact, for real-time audio and video, machine learning has been studied for many years, and the real-time image recognition that we have shared is just one of the applications. We can also use deep learning to do super-resolution. This time we will share the basic framework of deep learning for super-resolution, and various derived network models, some of which also have good performance in meeting real-time performance.
Machine learning and deep learning
For developers who are less exposed to machine learning and deep learning, they may not be able to understand the difference between the two, and even think that machine learning is deep learning. In fact, we can easily distinguish this concept with a picture.
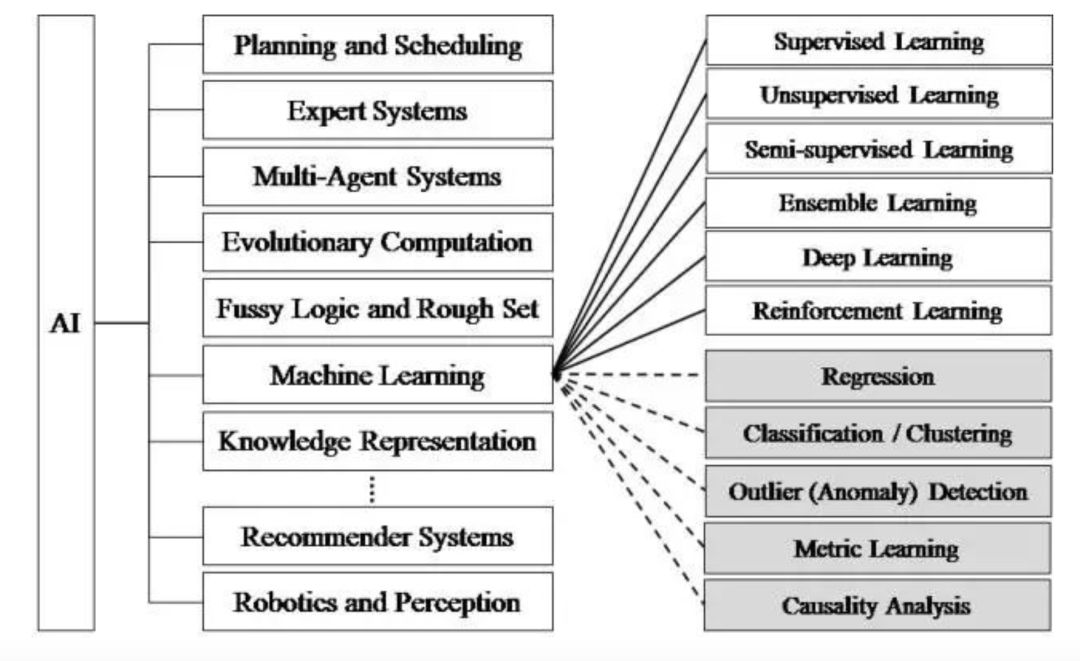
In the 1950s, there was the concept of artificial intelligence, and later there were some more basic applications, such as chess. But in the 1970s, due to hardware performance constraints and lack of training data sets, artificial intelligence experienced a trough. Artificial intelligence includes many things, such as machine learning, scheduling algorithms, and expert systems. It was only in the 1980s that more machine learning applications began to appear, such as using algorithms to analyze data and make judgments or predictions. Machine learning includes logic trees, neural networks, etc. And deep learning is a method in machine learning, derived from neural networks.
What is super resolution?
Super resolution is a concept based on the human visual system. David Hubel and Torsten Wiesel, winners of the 1981 Nobel Prize in Medicine, discovered that the information processing methods of the human visual system are hierarchical. The first layer is the original data input. When a person sees a face image, they will first identify the edges such as points and lines. Then enter the second layer, will identify some basic elements in the image, such as eyes, ears, nose. Finally, an object model is generated, which is a complete face.
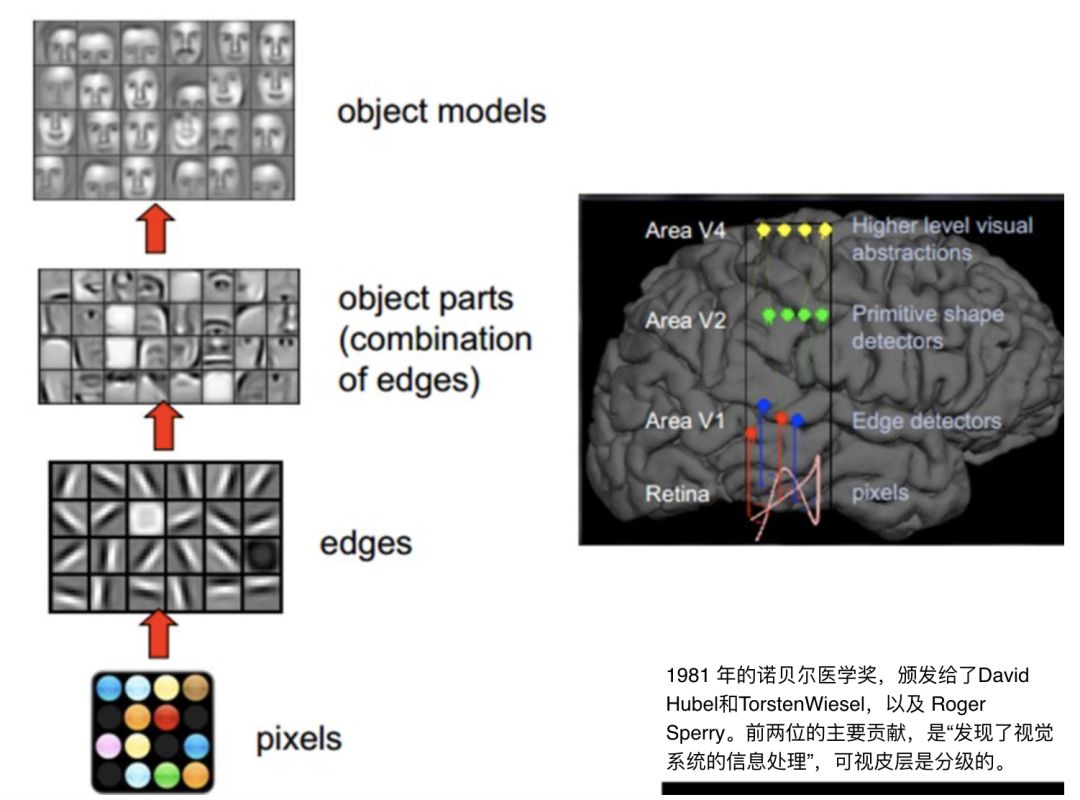
And our convolutional neural network in deep learning (as an example in the figure below) imitates the processing process of the human visual system. For this reason, computer vision is one of the best application areas for deep learning. Super resolution is a classic application in computer vision.
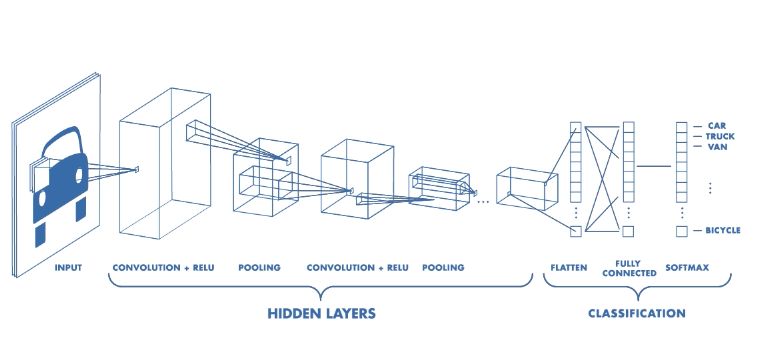
Super-resolution is a method of improving image resolution through software or hardware methods. Its core idea is to trade time bandwidth for spatial resolution. Simply put, when I can't get a super high resolution image, I can take a few more images, and then combine this series of low resolution images into a high resolution image. This process is called super-resolution reconstruction.
Why can super resolution improve the resolution of a picture by taking a few more images?
This involves jitter. The anti-shake that we often say when taking photos is actually a more obvious anti-shake, but there is always a slight jitter. There are subtle differences between each image of the same scene. These tiny jitters actually contain additional information about the scene. If you merge them, you will get a clearer image.
Someone may ask, why do we need super-resolution technology because our mobile phones can be equipped with 20 million front and back? Are there not many application scenarios for this technology?
Actually not. Anyone who knows photography knows it. On the same photosensitive component, the higher the resolution of the captured image, the smaller the area occupied by a single pixel on the photosensitive component, the lower the light transmission rate. When your pixel density reaches a certain level, it will Bring a lot of noise and directly affect the image quality. Super resolution can solve this problem. There are many applications for super resolution, such as:
Digital HD, through this method to improve the resolution
Microscopic imaging: synthesize a series of low-resolution images under a microscope to obtain high-resolution images
Satellite images: used for remote sensing satellite imaging to improve image accuracy
Video restoration: the technology can be used to restore videos, such as old movies
However, there are many situations where we only have one image and cannot take multiple images. So how to do super resolution? This requires machine learning. A typical example is a “black technology†proposed by Google in 2017. They can use machine learning to eliminate mosaics in video images. Of course, this black technology also has certain limitations. The following figure is an example. The neural network it trains is for face images. If the mosaic image you give is not a face, it cannot be restored.

Super-resolution neural network principle
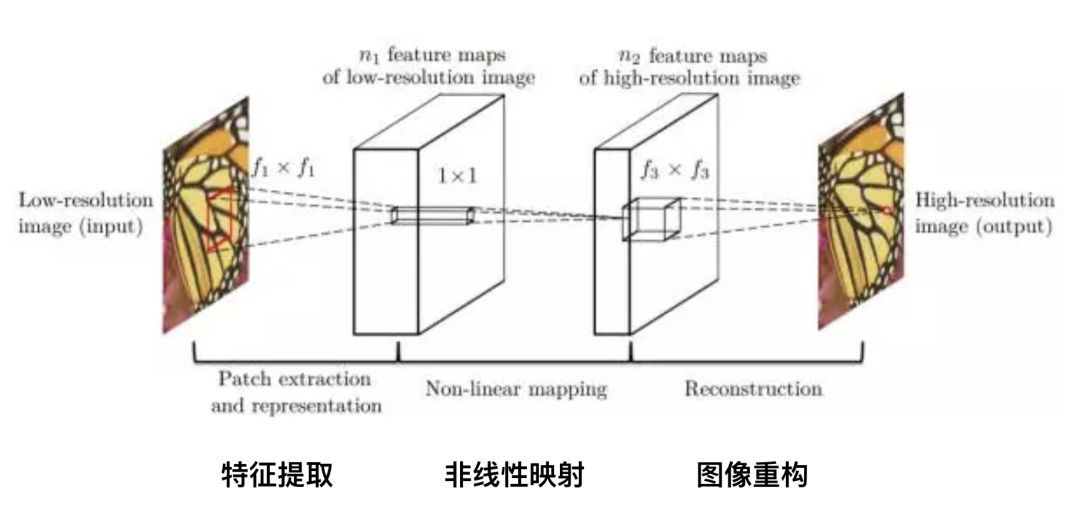
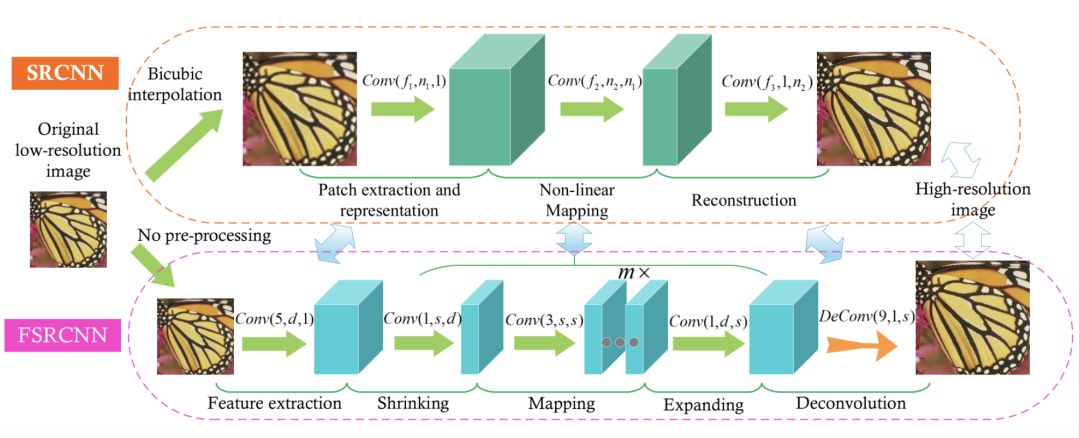
Super-Resolution CNN (SRCNN) is the first model applied in the field of super-resolution deep learning. The principle is relatively simple. It has three layers of neural networks, including:
Feature extraction: the low-resolution image gets a fuzzy image through binomial difference, and extracts image features from it. Channel is 3, the size of the convolution kernel is f1*f1, and the number of convolution kernels is n1;
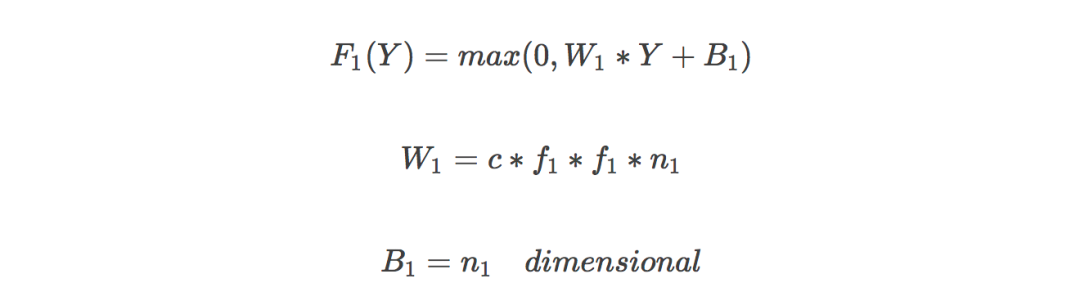
Non-linear mapping: mapping low-resolution image features to high-resolution, the size of the convolution kernel is 1*1;
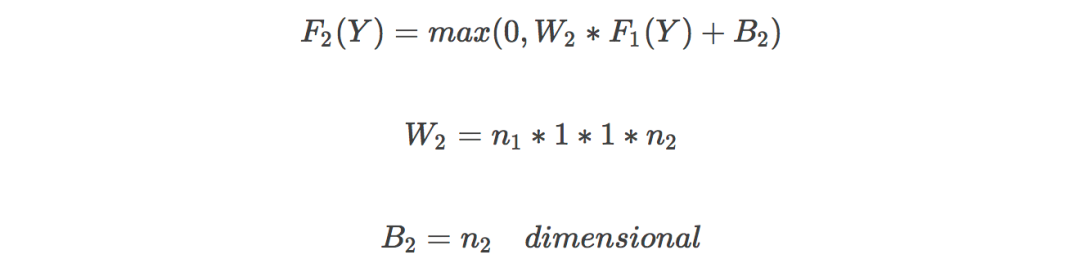
Image reconstruction: restore details and get clear high-resolution images, the convolution kernel is f3*f3;
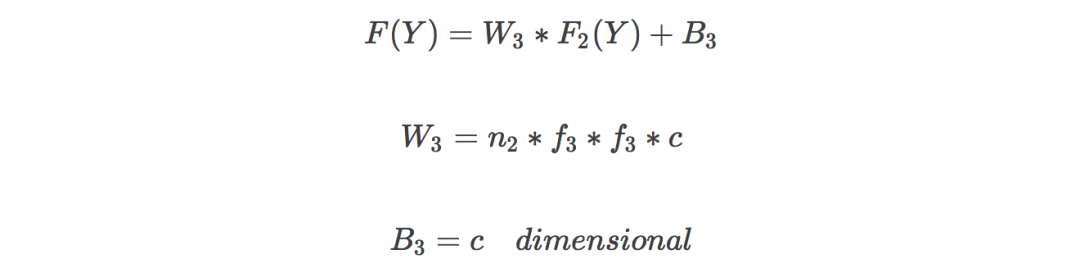
Parameter adjustment is the more mysterious part of the neural network, and it is also the most criticized part. Many people think that parameter adjustment is much like seeing a doctor in traditional Chinese medicine, usually lacking theoretical basis. Here are a few examples of training time and peak signal-to-noise ratio (PSNR, a parameter used to judge image quality, the higher the better) when n1 takes different values.

In training, using Mean Squared Error (MSE) as the loss function is conducive to obtaining higher PSNR.
What is the result of the training? In the table below, the results of several traditional methods and the SRCNN method are compared. The leftmost column is the image set, and the training time and peak signal-to-noise ratio of the image are listed on the right for each method. It can be seen that although there are some pictures, the results obtained by traditional methods are better than deep learning, but in general, deep learning is slightly better and even takes less time.
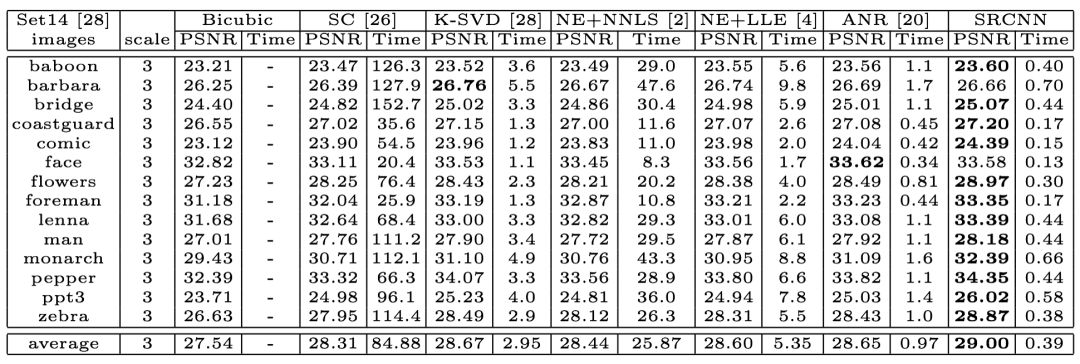
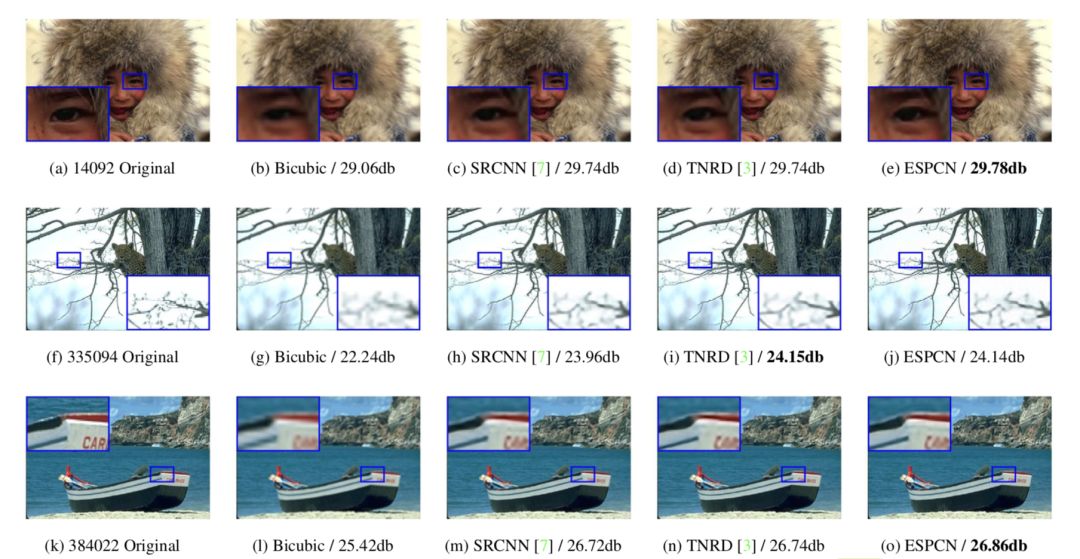
Some people say that a picture is worth a thousand words. So what is the actual picture effect? We can look at the following two sets of pictures. The first image in each group is the original image with small resolution, and the large image with high resolution is realized by different methods later. Compared with the traditional method, SRCNN has clearer picture edges and better detail recovery. The above is the original super-resolution deep learning model.

9 super-resolution neural network models
SRCNN is the first super-resolution neural network model. After the emergence of the SRCNN model, it is more applied to super-resolution neural network models. We share a few below:
FSRCNN
Compared with SRCNN, this method does not need to use binomial difference for the original picture, and can directly process small-resolution images. After extracting the feature value, the image is reduced, and then the mapping, expending, and deconvolution layers are passed to obtain a high-resolution image. Its advantage is that reducing the picture can reduce the training time. At the same time, if you need to get pictures of different resolutions, you can train the deconvolution layer separately, which saves time.
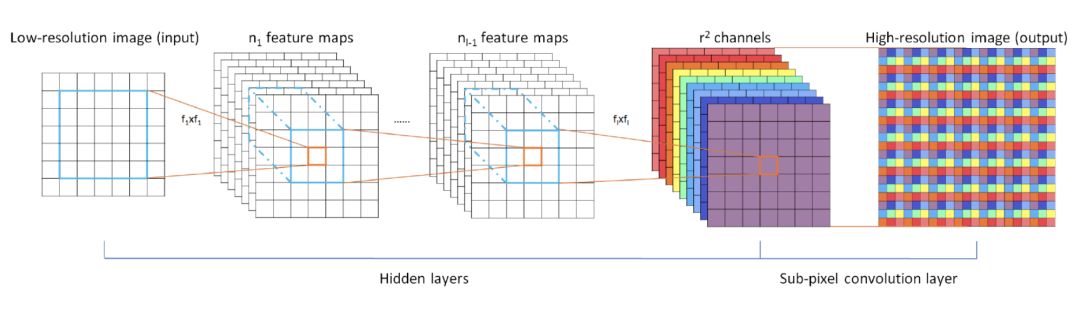
ESPCN
This model is trained based on small images. Finally r² channels are extracted. For example, if I want to enlarge the image to 3 times of the original image, then r is the zoom factor of 3 and Channel is 9. By expanding a pixel into a 3x3 matrix, which is simulated as a pixel matrix, the effect of super-resolution is achieved.
The experimental results of super-resolution processing on real-time video are also very good. To zoom the video in 1080 HD format by 3 times, SRCNN needs 0.435s per frame, while ESPCN only needs 0.038s.
VDSR
This is a model awarded in 2016. All of us who do video codec know that there are residuals between images. It believes that between the original low-resolution picture and the high-resolution picture, the low-frequency components are almost the same, and the high-frequency components that are missing are the picture details. When training, you only need to train for the high-frequency components.
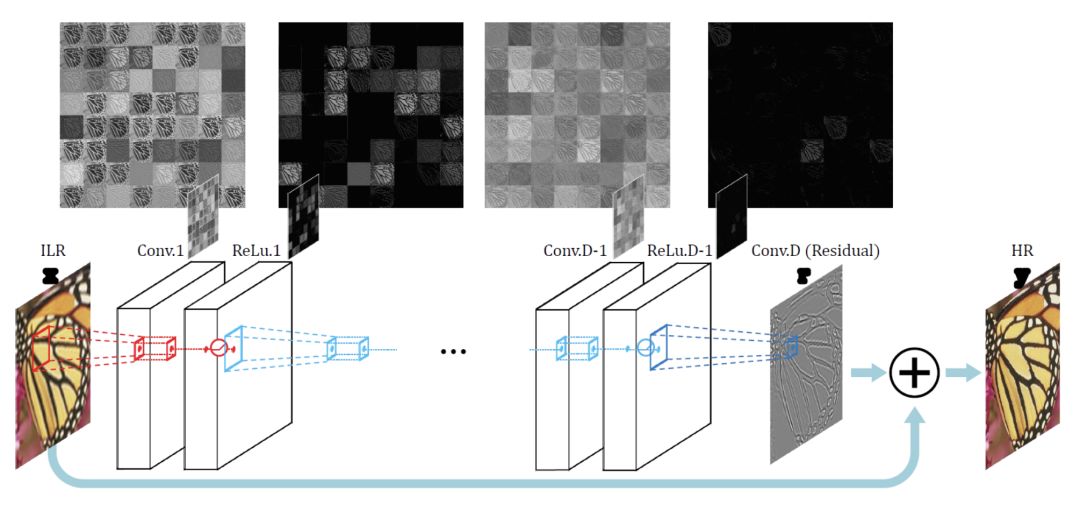
Therefore, its input is divided into two parts, one is to use the entire original image as one input, and the other is to train the residuals and get an input. Add the two to get a high-resolution image. In this way, the training speed is greatly accelerated, and the convergence effect is better.
DRCN
It is divided into three layers. But in the non-linear mapping layer, it uses a recursive network, that is, the data loops through the layer multiple times. Unrolling this loop is equivalent to multiple convolutional layers in series using the same set of parameters.
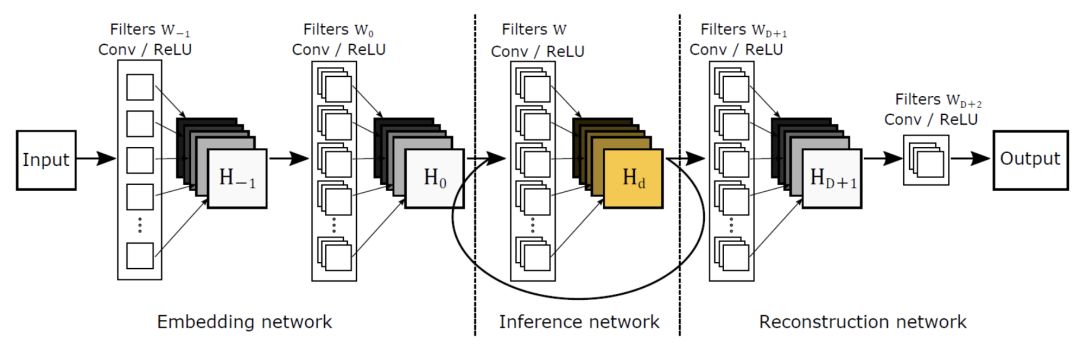
RED
Each convolutional layer corresponds to a non-convolutional layer. Simply put, it can be understood as encoding a picture and then decoding it immediately. Its advantage is that it solves the problem of disappearing gradient and can restore a cleaner picture. It has a similar idea to VDSR. The training of the intermediate convolutional layer and deconvolutional layer is for the residual of the original picture and the target picture. Finally, the original image will be added to the training output to get a high-resolution image.
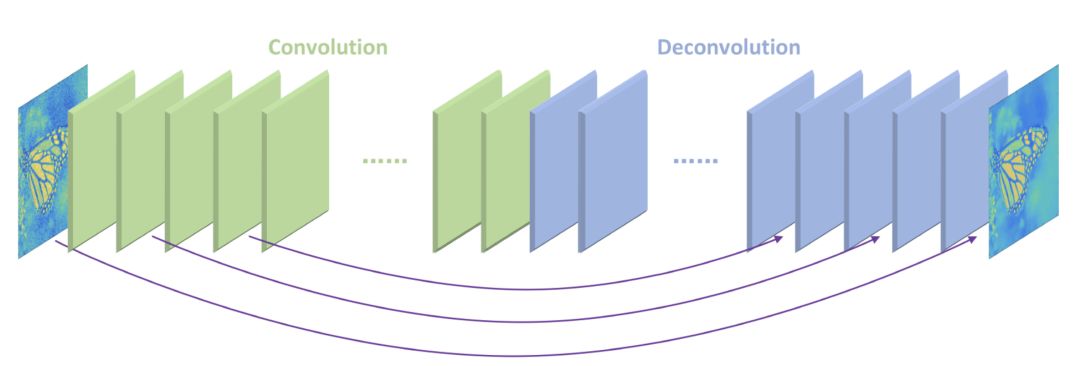
DRRN
In this model, you can see the shadow of DRCN and VDSR. It uses a deeper network structure to improve performance. There are many image enhancement layers. It can be understood that a blurry picture becomes clearer one level after multiple enhancement layers, and finally a high-definition picture is obtained. You can find the source code on Github called tyshiwo.
LapSRN
The special feature of LapSRN is the introduction of a hierarchical network. Each level only enlarges the original image twice, and then adds the residual error to obtain a result. If the picture is enlarged 8 times, the performance of this processing will be higher. At the same time, at each level of processing, an output result can be obtained.
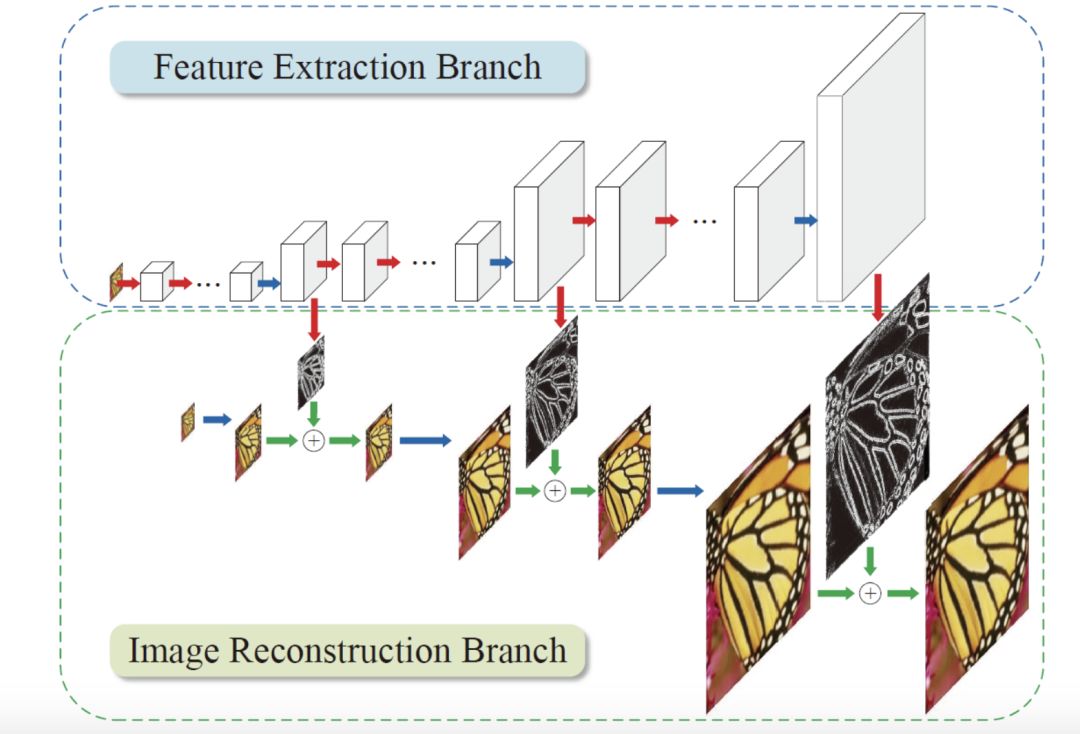
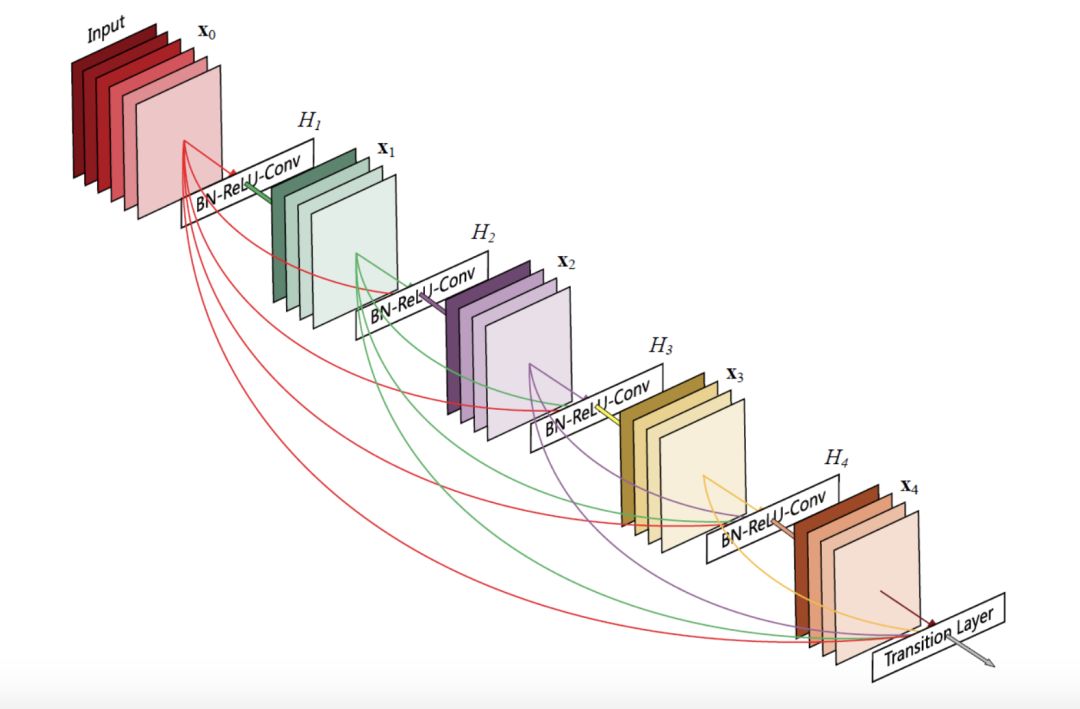
SRDenseNet
It introduces a Desent Block structure. The feature values ​​trained by the previous network will be passed to the next network, and all features will be connected in series. The advantage of this is to reduce the problem of gradient disappearance and reduce the number of parameters. Moreover, the subsequent layers can reuse the feature values ​​obtained from the previous training, without repeated training.
SRGAN
It can use perceptual loss and adversarial loss to improve the recovered picture.
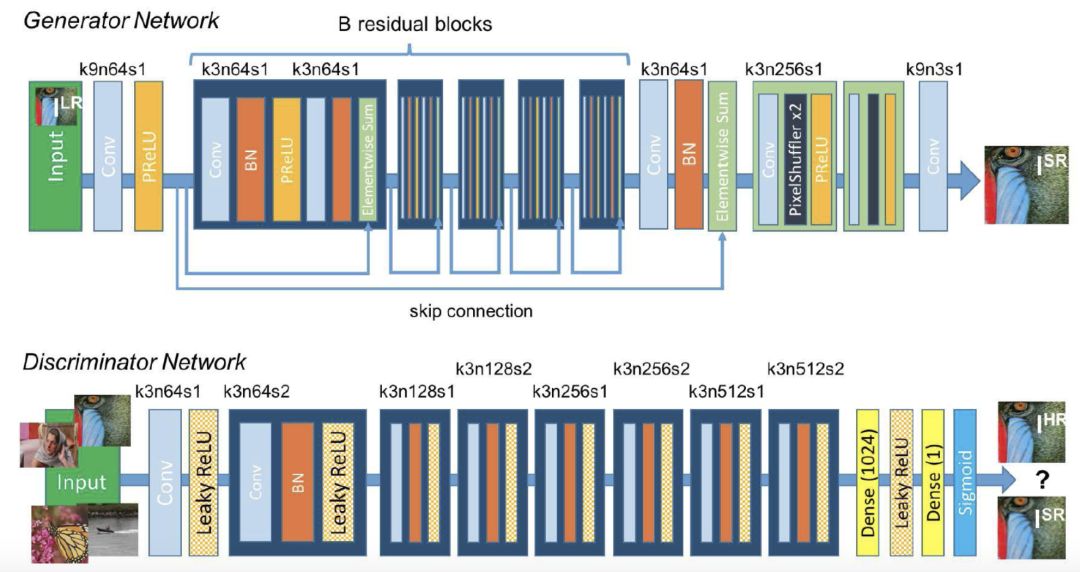
There are two networks in this model. One is the generation network and the other is the discrimination network. The former will generate a high-resolution image, and the latter will determine whether the image is the original image. If the result is "No", then The former will be trained and generated again until it can deceive the discriminant network.
The above neural network models can all be applied to video processing, but the actual application also needs to consider many factors, such as system platform, hardware configuration, and performance optimization. In fact, in addition to super-resolution, machine learning and real-time audio and video can be combined in many application scenarios, such as audio and video experience optimization, pornography, QoE improvement, etc. At the RTC 2018 Real-Time Internet Conference in September this year, we will invite technical experts from Google, Meitu, Sogou and other companies to share more practical experience and dry goods.
1000W Ptc Room Heater,Ptc Fan Heater,Ptc Tower Heater,Ptc Electric Fan Heater
Foshan Shunde Josintech Electrical Appliance Technology Co.,Ltd , https://www.josintech.com