A new representation learning method-contrast predictive coding
The latest research of DeepMind proposes a new representation learning method-contrast predictive coding. Researchers conducted experiments in multiple fields: audio, image, natural language, and reinforcement learning, proving that the same mechanism can learn meaningful high-level information in all these fields and is superior to other methods.
In 2013, Bengio et al. published a review on representation learning, defining representation learning as “learning the representation of data so that useful information can be extracted more easily when constructing classifiers or other predictorsâ€, and no Many advances in supervised feature learning and deep learning are included in the category of representation learning.
Today, in the latest paper Representation Learning with Contrastive Predictive Coding, DeepMind proposes a new representation learning method—Contrastive Predictive Coding (CPC), and applies it to various data modalities, images, and voices. , Natural language and reinforcement learning have proved that the same mechanism can learn meaningful high-level information in all these fields and is superior to other methods.

Predictive coding ideas
Using hierarchical differentiable models to learn high-level representations from labeled data in an end-to-end manner is one of the biggest successes of artificial intelligence to date. These technologies make the manually specified features redundant to a large extent, and greatly improve the current best technology in some real-world applications. However, these technologies still have many challenges, such as data efficiency, robustness, or generalization capabilities.
Improvement means that learning requires features that are not specifically addressed to a single supervision task. For example, when pre-training a model for image classification, the features can be transferred to other image classification domains quite well, but some information, such as color or counting ability, is also lacking, because this information has nothing to do with classification, but may be related to other images. Task-related, such as image captioning. Similarly, the features used to transcribe human speech may not be suitable for speaker recognition or music type prediction. Therefore, unsupervised learning is an important cornerstone to achieve robust and universal representation learning.
Despite the importance of unsupervised learning, unsupervised learning has not yet achieved a breakthrough similar to supervised learning: modeling advanced representations from raw observations is still difficult to achieve. In addition, it is not always clear what the ideal representation is and whether it can be learned without additional supervised learning or specialization for a particular data modality.
One of the most common strategies for unsupervised learning is to predict the future, missing information, or contextual information. This idea of ​​predictive coding is one of the oldest techniques in data compression signal processing. In neuroscience, predictive coding theory suggests that the brain can predict observations at different levels of abstraction.
Some recent work in unsupervised learning has successfully used these concepts to learn word representations by predicting neighboring words. For images, predicting the color from the relative position of the grayscale or image patches has also proven useful. We assume that these methods are effective, partly because the context in which we predict related values ​​is usually conditionally dependent on the same shared high-level underlying information. By treating it as a prediction problem, we can automatically infer that these features are relevant to representation learning.
This article has the following contributions:
First, we compress high-dimensional data into a more compact latent embedding space, in which conditional prediction is easier to model.
Second, we use a powerful autoregressive model in this latent space to predict the future.
Finally, we rely on the Noise-Contrastive Estimation loss function, which is similar to the method of learning word embeddings in natural language models, allowing end-to-end training of the entire model.
Contrast predictive coding
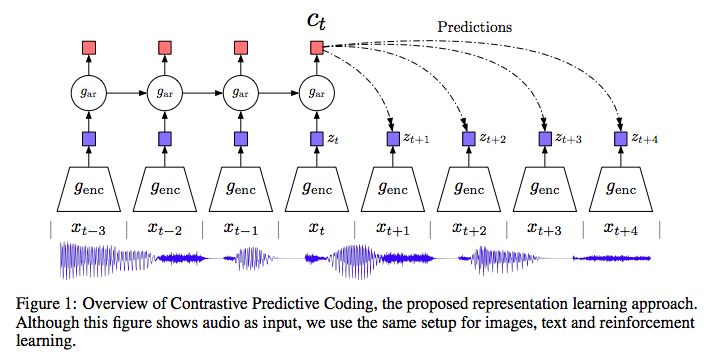
Figure 1: Overview of the comparison predictive coding, that is, our proposed representation learning method. Although the picture uses audio as input, we use the same settings for images, text, and reinforcement learning.
Figure 1 shows the architecture of the comparative predictive coding model. First, the nonlinear encoder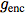 Sequence of observations
Sequence of observations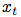 Mapping to latent representation sequence
Mapping to latent representation sequence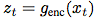 , May have a lower time resolution. Next, the autoregressive model
, May have a lower time resolution. Next, the autoregressive model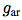 Summarize all in the potential space
Summarize all in the potential space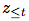 , And generate a contextual latent representation
, And generate a contextual latent representation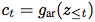 .
.
We are not directly using generative models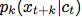 To predict future observations
To predict future observations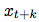 . Instead, we modeled the density ratio and retained
. Instead, we modeled the density ratio and retained 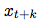
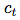 The formula for the interactive information between:
The formula for the interactive information between:

among them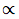 Represents "proportional."
Represents "proportional."
In our experiment, we use linear transformation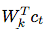 Different for each step k
Different for each step k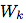 For forecasting, you can also use nonlinear networks or recurrent neural networks.
For forecasting, you can also use nonlinear networks or recurrent neural networks.
Experiments in 4 different fields: speech, image, NLP and reinforcement learning
We propose benchmarks for four different application areas: speech, image, natural language and reinforcement learning. For each field, we train the CPC model and explore the content of "representations" through linear classification tasks or qualitative evaluation; in reinforcement learning, we measure how the auxiliary CPC loss accelerates the learning of the agent.
Audio
For speech, we used a 100-hour sub-data set from the public LibriSpeech data set. Although the data set does not provide labels other than the original text, we used the Kaldi toolkit to obtain a forced alignment call sequence and pre-trained the model on Librispeech. The data set contains voices from 251 different speakers.
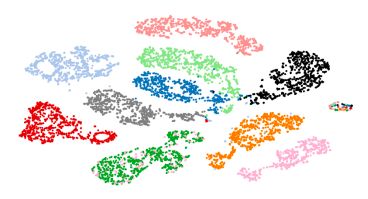
Figure 2: A t-SNE visualization of an audio representation of a subset of 10 speakers. Each color represents a different speaker.
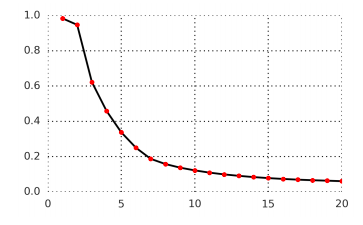
Figure 3: Predicting the contrast loss of 1 to 20 potential steps in the future in the speech waveform, the average accuracy of the positive sample prediction. The model predicts at most 200 ms in the future because each step contains 10ms of audio.
Image (Vision)
In the visual representation experiment, we use the ImageNet dataset. We use ResNet v2 101 architecture as the image encoder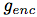 To extract the CPC representation (the encoder is not pre-trained). After unsupervised training, a linear layer is trained to measure the classification accuracy of ImageNet tags.
To extract the CPC representation (the encoder is not pre-trained). After unsupervised training, a linear layer is trained to measure the classification accuracy of ImageNet tags.
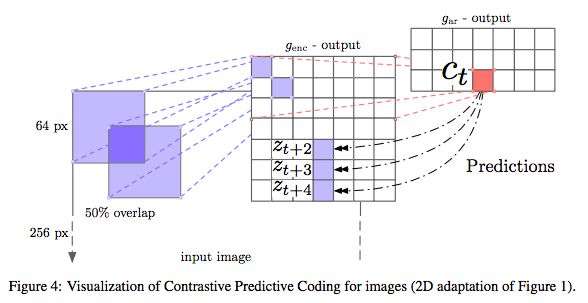
Figure 4: Visualization of contrast predictive coding in image experiment

Figure 5: Each row shows the image patches of a certain neuron that activates the CPC architecture
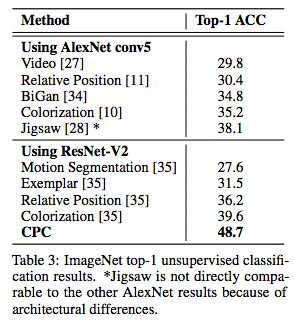
Table 3: ImageNet top-1 unsupervised classification results.
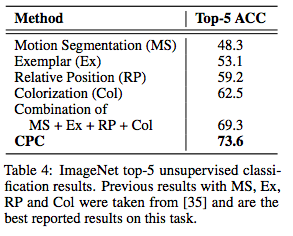
Table 4: ImageNet top-5 unsupervised classification results.
Table 3 and Table 4 show the classification accuracy of CPC model in ImageNet top-1 and top-5 compared with state-of-the-art. Although the relative domain is agnostic, the accuracy of the CPC model in top-1 is increased by 9% compared to the current optimal model, and the accuracy in top-5 is increased by 4%.
natural language
In the natural language experiment, we first learn our unsupervised model on the BookCorpus dataset, and evaluate the model's ability as a general feature extractor by using CPC representation for a set of classification tasks.
For the classification task, we used the following data sets: We used the following data sets: movie review sentiment (MR), customer product reviews (CR), subjectivity/objectivity, opinion polarity (MPQA) and question type classification (TREC) .
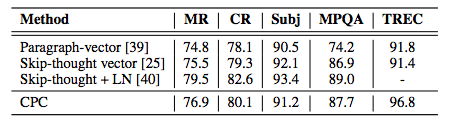
Table 5: Classification accuracy of five common NLP benchmarks.
The results of the evaluation task are shown in Table 5.
Reinforcement learning
Finally, we evaluated DeepMind Lab's five unsupervised learning methods for reinforcement learning in a 3D environment: rooms_watermaze, explore_goal_locations_small, seekavoid_arena_01, lasertag_three_opponents_small, and rooms_keys_doors_puzzle.
Here, we use the standard batched A2C agent as the basic model, and add CPC as the auxiliary loss. The learned representation encodes the distribution of its future observations.
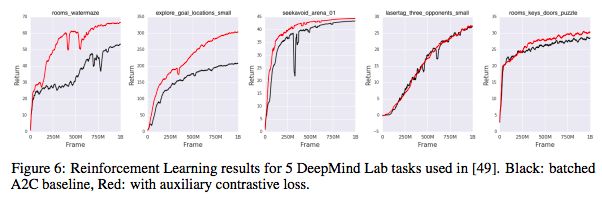
Figure 6: Reinforcement learning results of five DeepMind Lab tasks. Black: batched A2C baseline, red: add auxiliary contrast loss
As shown in Figure 6, after 1 billion frames of training, for 4 out of 5 games, the agent's performance has improved significantly.
in conclusion
In this article, we propose Comparative Predictive Coding (CPC), which is a framework for extracting compact latent representations to encode future observations. CPC combines autoregressive modeling and noise contrast estimation with the intuition of predictive coding to learn abstract representations in an unsupervised manner.
We tested these representations in multiple areas: audio, image, natural language, and reinforcement learning, and achieved strong or optimal performance when used as independent features. The simplicity and low computational requirements of the training model, as well as the encouraging results when used with the main loss in the field of reinforcement learning, show the exciting development of unsupervised learning, and this learning is generally applicable to more data modalities .
Dongguan Guancheng Precision Plastic Manufacturing Co., Ltd. , https://www.dpowergo.com